旋转位置编码(RoPE)原理详解
RoPE作者苏剑林提出RoPE时的想法以及求解过程:https://spaces.ac.cn/archives/8265
本篇文章参考视频,感谢up
旋转矩阵
一个例子
旋转位置编码的核心是通过由 sin 和 cos 函数构成的二维旋转矩阵对二维向量进行旋转,$\theta$ 是旋转角度。比如针对 x 轴上的 (1, 0) 向量,旋转 $\theta$ 角,其长度不会改变,旋转后的向量等于原向量 * $\theta$ 角旋转矩阵。
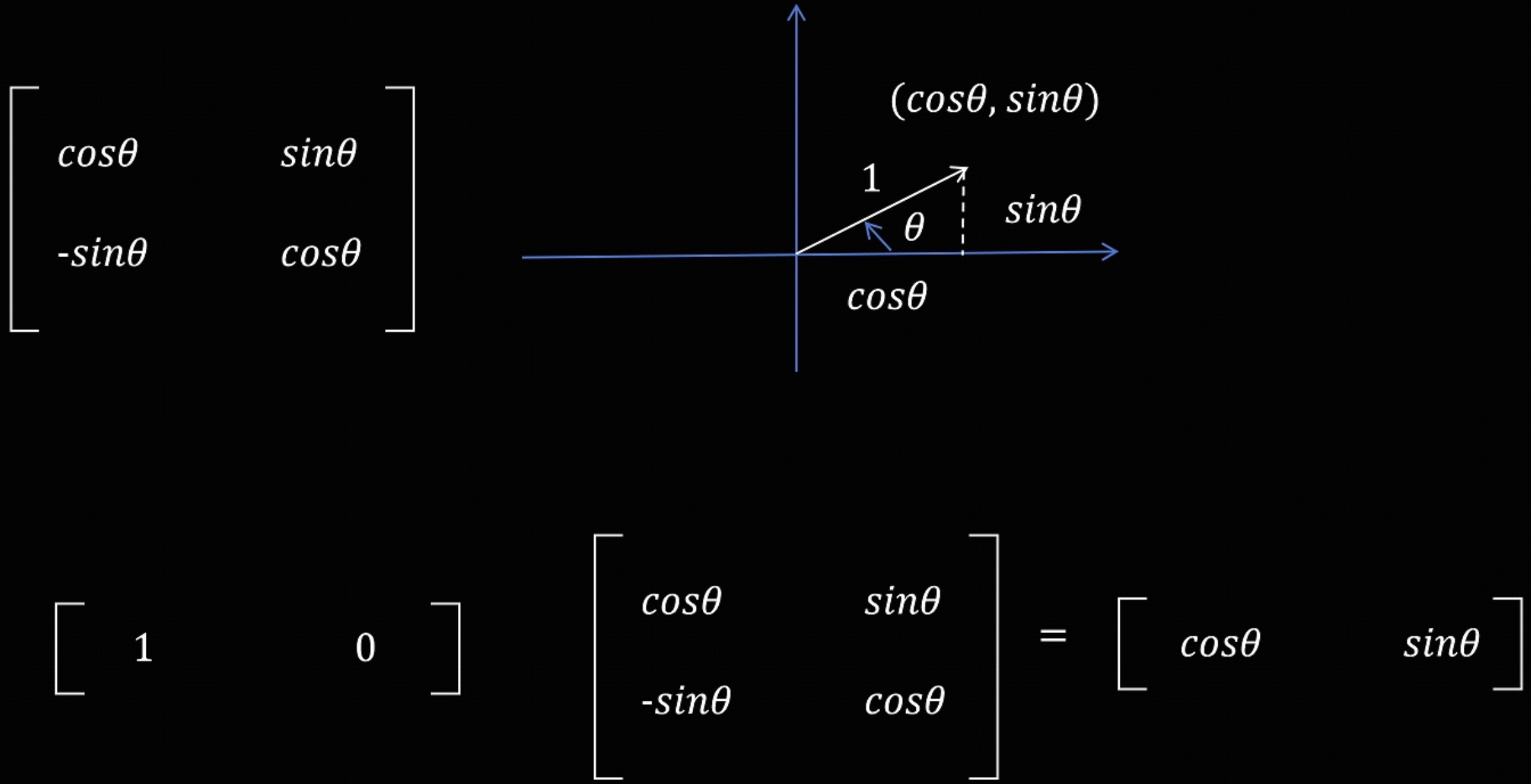
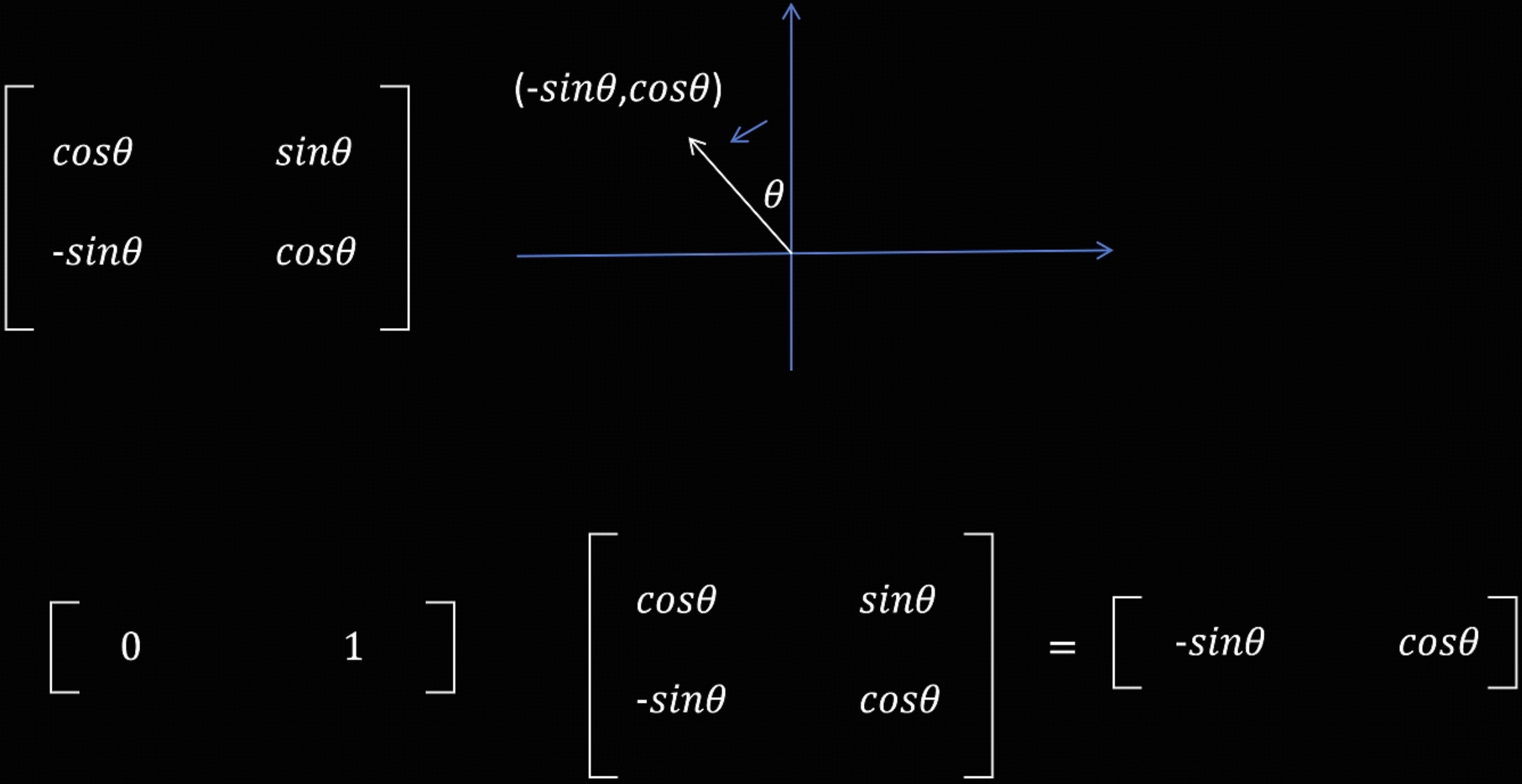
(1, 0) 和 (0, 1) 是坐标系的一个基,这个基通过旋转矩阵都逆时针旋转了 $\theta$ 角,那么这个基里所有的向量都跟着被旋转了 $\theta$ 角。
旋转矩阵的作用
假设一个向量长度为 r,其与 x 轴的夹角为 $\theta$,旋转矩阵为逆时针旋转 $\beta$,通过矩阵乘法可得到如下表示,最后利用三角公式可以得到:经过旋转的向量与原始向量相比,其长度不变,角度逆时针旋转了 $\theta$ 角。

旋转矩阵的两个性质
- 一个向量先旋转 $\theta_1$,再旋转 $\theta_2$,等于一次性旋转 $\theta_1+\theta_1$。
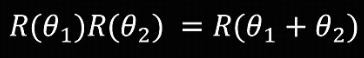
- 角度为 $\theta$ 的旋转矩阵的转置等于角度为 $-\theta$ 的旋转矩阵。
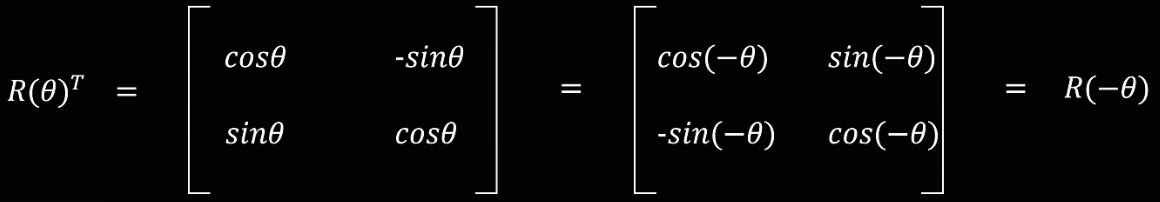
相对位置编码
二维向量示例
注意力机制中需要计算 q 和 k 的点积,等价于 q * k 的转置,直接计算点积是没有考虑位置信息的。如果 q 的位置是 m, k 的位置是 n,那么对 q 旋转 m,对 k 旋转 n,再做点积,得到的结果就包含了它们之间的相对位置信息。
扩展到高维向量
将维度两两组合在一起进行旋转,两个特征维度为一组,每组在它们两个特征组成的子空间内进行旋转。特征的组合可以随意选取,任意两个特征为一组都可以。
图中的 m 代表位置,比如处于序列第一个位置的 token 的 m 就为0,以此类推;f 代表 sin 和 cos 的频率,在这个公式里,频率最大的是第一个二维子空间,频率为 1,频率最小的是最后一个二维子空间,频率接近 10000。
不同频率的三角函数对应不同尺度的位置信息。低频信号变化缓慢,适合编码长距离依赖(远距离token之间的关系);高频信号变化迅速,适合编码短距离依赖(邻近token之间的关系)。若所有子空间频率相同,模型只能捕捉到单一尺度的位置模式(如仅能区分相邻词,无法建模长句依赖)。


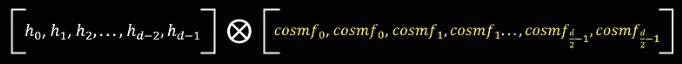

通过上述计算方式来实现 RoPE,使用图中向量逐位对应相乘。
HuggingFace 中 Llama 的 RoPE 代码实现
- 计算频率
1 | |
其中,self.base 为 10000。
- 计算正弦值和余弦值
1 | |
- 对
q和k添加旋转位置编码信息
1 | |
对于与 sin 相乘的 q 和 k 需要有一半是负值,但是不一定要按照原始公式来实现,只需要保证其中有一半是负值即可,负值元素可以任意选取。
在HuggingFace论坛的讨论中,有人指出了这个问题:对于查询向量 【1, 2, 3, 4, 5, 6】,期望的输出应该是 【-2, 1, -4, 3, -6, 5】(相邻对旋转),但rotate_half函数返回的是 【-4, -5, -6, 1, 2, 3】(前后半分割)。这两种方法在数学上被认为是等价的,HuggingFace可以直接加载Meta官方发布的检查点权重,这表明两种实现在某种程度上是兼容的,另外,模型在训练过程中会学习适应特定的RoPE实现方式