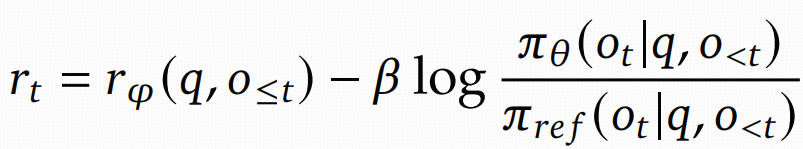1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
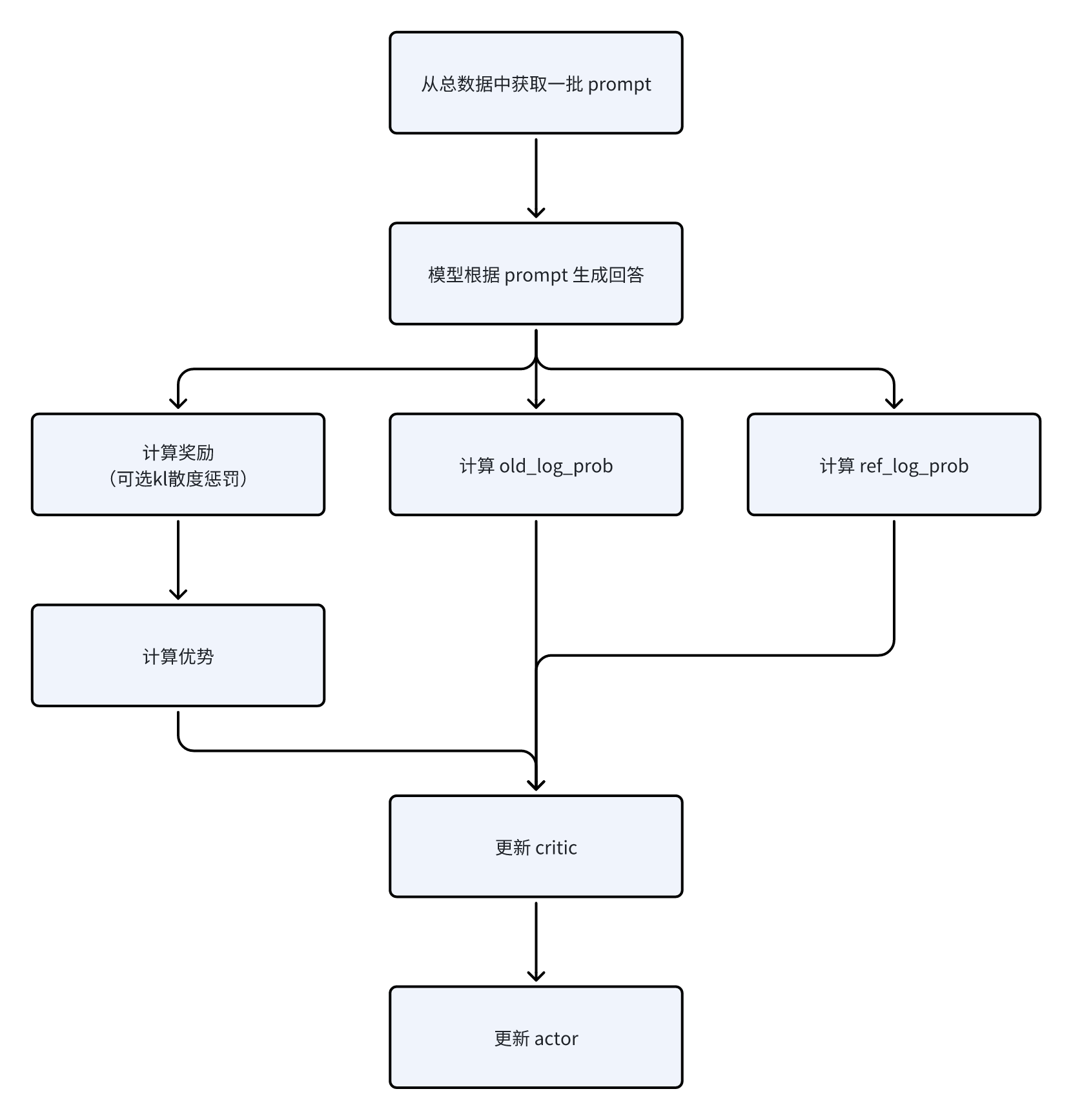
| def fit(self):
"""
The training loop of PPO.
The driver process only need to call the compute functions of the worker group through RPC
to construct the PPO dataflow.
The light-weight advantage computation is done on the driver process.
"""
...
for epoch in range(self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
metrics = {}
timing_raw = {}
with marked_timer("start_profile", timing_raw):
self._start_profiling(
not prev_step_profile and curr_step_profile
if self.config.global_profiler.profile_continuous_steps
else curr_step_profile
)
batch: DataProto = DataProto.from_single_dict(batch_dict)
batch.non_tensor_batch["uid"] = np.array(
[str(uuid.uuid4()) for _ in range(len(batch.batch))], dtype=object
)
gen_batch = self._get_gen_batch(batch)
gen_batch.meta_info["global_steps"] = self.global_steps
gen_batch = gen_batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
is_last_step = self.global_steps >= self.total_training_steps
with marked_timer("step", timing_raw):
with marked_timer("gen", timing_raw, color="red"):
if not self.async_rollout_mode:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
else:
gen_batch_output = self.async_rollout_manager.generate_sequences(gen_batch)
timing_raw.update(gen_batch_output.meta_info["timing"])
gen_batch_output.meta_info.pop("timing", None)
if self.config.algorithm.adv_estimator == AdvantageEstimator.REMAX:
if self.reward_fn is None:
raise ValueError("A reward_fn is required for REMAX advantage estimation.")
with marked_timer("gen_max", timing_raw, color="purple"):
gen_baseline_batch = deepcopy(gen_batch)
gen_baseline_batch.meta_info["do_sample"] = False
if not self.async_rollout_mode:
gen_baseline_output = self.actor_rollout_wg.generate_sequences(gen_baseline_batch)
else:
gen_baseline_output = self.async_rollout_manager.generate_sequences(gen_baseline_batch)
batch = batch.union(gen_baseline_output)
reward_baseline_tensor = self.reward_fn(batch)
reward_baseline_tensor = reward_baseline_tensor.sum(dim=-1)
batch.pop(batch_keys=list(gen_baseline_output.batch.keys()))
batch.batch["reward_baselines"] = reward_baseline_tensor
del gen_baseline_batch, gen_baseline_output
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
batch = batch.union(gen_batch_output)
if "response_mask" not in batch.batch.keys():
batch.batch["response_mask"] = compute_response_mask(batch)
if self.config.trainer.balance_batch:
self._balance_batch(batch, metrics=metrics)
batch.meta_info["global_token_num"] = torch.sum(batch.batch["attention_mask"], dim=-1).tolist()
with marked_timer("reward", timing_raw, color="yellow"):
if self.use_rm:
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
if self.config.reward_model.launch_reward_fn_async:
future_reward = compute_reward_async.remote(data=batch, reward_fn=self.reward_fn)
else:
reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)
with marked_timer("old_log_prob", timing_raw, color="blue"):
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
entropys = old_log_prob.batch["entropys"]
response_masks = batch.batch["response_mask"]
loss_agg_mode = self.config.actor_rollout_ref.actor.loss_agg_mode
entropy_agg = agg_loss(loss_mat=entropys, loss_mask=response_masks, loss_agg_mode=loss_agg_mode)
old_log_prob_metrics = {"actor/entropy": entropy_agg.detach().item()}
metrics.update(old_log_prob_metrics)
old_log_prob.batch.pop("entropys")
batch = batch.union(old_log_prob)
if "rollout_log_probs" in batch.batch.keys():
from verl.utils.debug.metrics import calculate_debug_metrics
metrics.update(calculate_debug_metrics(batch))
if self.use_reference_policy:
with marked_timer("ref", timing_raw, color="olive"):
if not self.ref_in_actor:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
else:
ref_log_prob = self.actor_rollout_wg.compute_ref_log_prob(batch)
batch = batch.union(ref_log_prob)
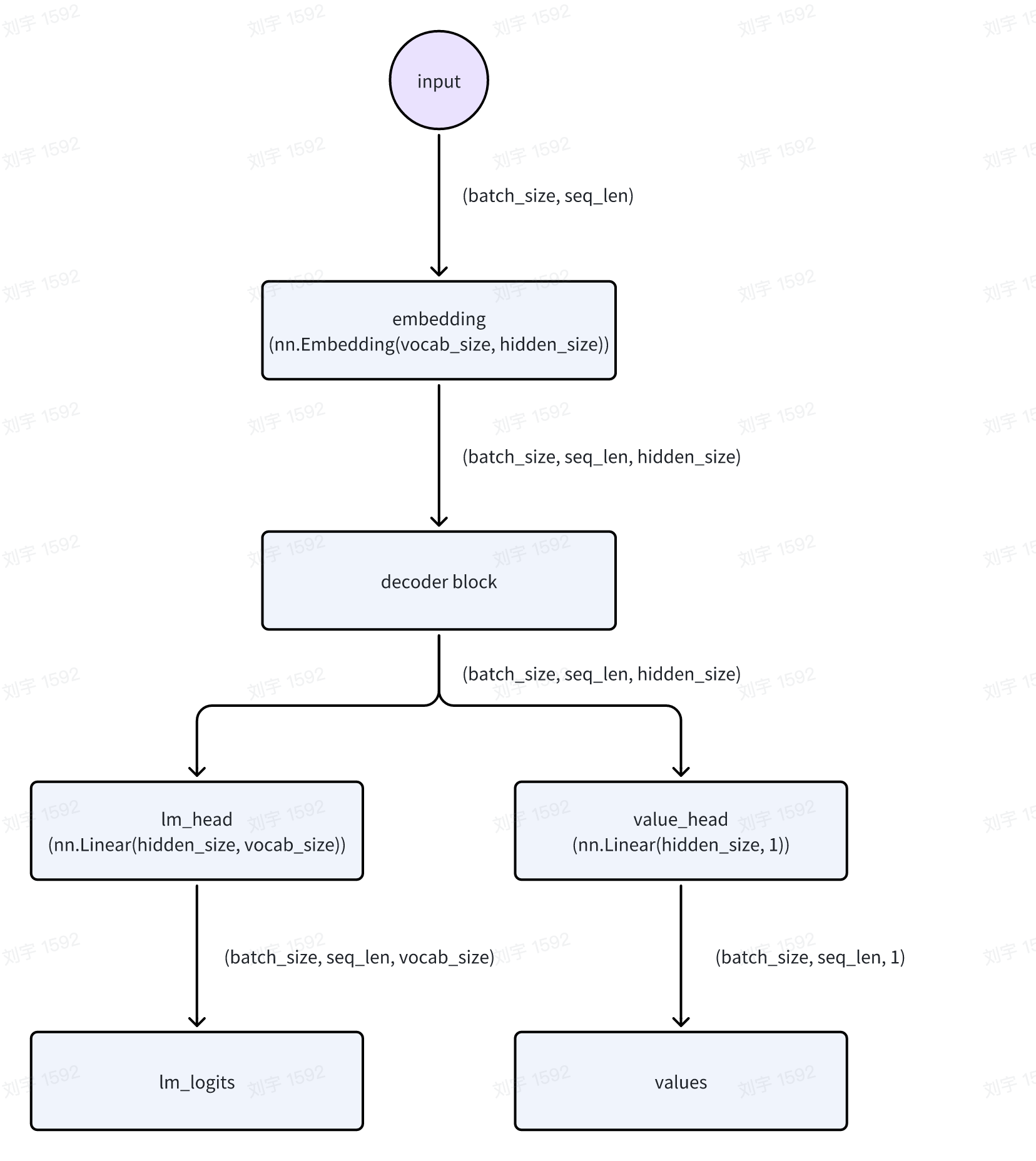
if self.use_critic:
with marked_timer("values", timing_raw, color="cyan"):
values = self.critic_wg.compute_values(batch)
batch = batch.union(values)
with marked_timer("adv", timing_raw, color="brown"):
reward_extra_infos_dict: dict[str, list]
if self.config.reward_model.launch_reward_fn_async:
reward_tensor, reward_extra_infos_dict = ray.get(future_reward)
batch.batch["token_level_scores"] = reward_tensor
if reward_extra_infos_dict:
batch.non_tensor_batch.update({k: np.array(v) for k, v in reward_extra_infos_dict.items()})
if self.config.algorithm.use_kl_in_reward:
batch, kl_metrics = apply_kl_penalty(
batch, kl_ctrl=self.kl_ctrl_in_reward, kl_penalty=self.config.algorithm.kl_penalty
)
metrics.update(kl_metrics)
else:
batch.batch["token_level_rewards"] = batch.batch["token_level_scores"]
norm_adv_by_std_in_grpo = self.config.algorithm.get(
"norm_adv_by_std_in_grpo", True
)
batch = compute_advantage(
batch,
adv_estimator=self.config.algorithm.adv_estimator,
gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
num_repeat=self.config.actor_rollout_ref.rollout.n,
norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
config=self.config.algorithm,
)
if self.use_critic:
with marked_timer("update_critic", timing_raw, color="pink"):
critic_output = self.critic_wg.update_critic(batch)
critic_output_metrics = reduce_metrics(critic_output.meta_info["metrics"])
metrics.update(critic_output_metrics)
if self.config.trainer.critic_warmup <= self.global_steps:
with marked_timer("update_actor", timing_raw, color="red"):
batch.meta_info["multi_turn"] = self.config.actor_rollout_ref.rollout.multi_turn.enable
actor_output = self.actor_rollout_wg.update_actor(batch)
actor_output_metrics = reduce_metrics(actor_output.meta_info["metrics"])
metrics.update(actor_output_metrics)
...
|